前言:框架模式不是一门写代码的学问,而是一门管理与组织代码的学问.其本质是一种软件开发的模型.与设计模式不同,设计模式是在解决一类问题时总结抽象出的公共方法(工厂模式,适配器模式,单例模式,观察者模式 ... ...),他们与某种具体的技术栈无关.一种框架模式往往使用了多种设计模式,切不要把他们的关系搞混.
更多信息可以看看这本《Developing Backbone Application》
一代目: 脚本式设计(无架构设计):

下面这样的代码,就是无任何设计模式的产物:
const a = document.createElement("a");
a.innerHTML = "www.google.com";
a.href = "//www.google.com";
a.style.position = "absolute";
a.style.top = 100;
a.onclick = function(){
console.log("google");
}
document.body.appendChild(a);
嗯嗯~先别吐槽,因为这种编码方式还是有他的优点的.
短短的几行代码,包含了创建,样式,绑定,插入. balabala.....
这种搞法虽有不少缺点,但麻雀虽小五脏俱全,所有功能一应俱全.早些年由于UI程序还处在一个懵懂期,
逻辑不算太复杂,代码量也不会太多.这样的搞法似乎也没有什么问题. 毕竟到达A B两点最短的距离就是直线,上述代码可以说是实现某功能的最短路径.
典型的例子就是 ASM (虽然汇编语言不是用来写UI的),他们共有的缺点是 :入口单一 功能简单 不可维护
让我们修改一下上面的逻辑:
function doCss(a) {
a.style.position = "absolute";
a.style.top = 100;
}
function doEvent(a) {
a.onclick = function(){
alert("google");
}
}
function doAttribute(a){
a.innerHTML = "www.google.com";
a.href = "//www.google.com";
}
const a = document.createElement("a");
doCss(a);
doEvent(a);
doAttribute(a)
document.body.appendChild(a);这里我们将一个功能拆分成了3个部分,即 外观 事件 和属性.
函数将他们重新分离成一个个独立的逻辑块,这样一定程度上达到了分离复用的目的,比如你想修改外观,就去doCss函数里去找...
就像有钱人追求更多的财富,权贵追求更多权利一样.
人类总在思考同一个问题, 我们能不能做得更好..
直到有一天...
二代目: 代码文件分离(CodeBehind):

对asp.net尤其是webForm,winForm模式熟悉的同学,肯定对aspx 和 aspx.cs 这2种文件非常了解.
aspx是视图文件,而对应的.cs文件是他的相关逻辑处理文件 事件驱动模式下,框架帮我们完成了基本的事件类型,我们要做的是在事件下完成相关业务逻辑.
在前端中,也可以找到二代目大人的影分身..
<html>
<head>
<link href="style.css" rel="stylesheet" />
</head>
<body>
<script src="bundle.js" ></script>
</body>
</html>各文件各司其职,编写的时候分离,在运行的时候合并.这样进一步降低了功能之间的耦合度. 视图看起来非常"清爽",对应的逻辑也被分离成一个个文件, 交由相应的开发人员处理.
如果你涉猎的技术范围很广,你会发现其实二代目大人已经出现在诸多成熟的技术栈中....
但是,没过多久伊甸园欢乐的笑声被下面这个需求打破...

为了实现他,在这里我只写伪代码了:
`购买苹果按钮`绑定事件如下:
1.int 苹果数变量 + 1;
2.显示苹果数控件的值 = 苹果数变量;
`购买梨按钮`绑定事件如下:
1.int 梨数变量 + 1;
2.显示梨数控件的值 = 梨数变量;
...`吃苹果`
...`吃梨`
这里比较困难的是 第2步
就是如果显示苹果数的控件是另一个程序员开发的黑盒, 如何修改其值?
于是程序员A 去找 程序员B 寻求是否存在对应的 get/set 方法.
程序员B说有, "有" 字还没落地, 开发买梨的程序员C 又踹门进来了,问了同样的问题, 后来才知道 开发吃苹果功能的程序员D正在路上...
于是程序员B 不得不把接口的详细信息写到 wiki中, 于是 程序员CDEFGHIJKMLN 都看了wiki 懂了.
完成这件事 程序员B 写wiki 花了 10分钟, 程序员CDEFGHIJKMLN 看wiki每人花 1分钟,一共团队成本 20分钟.
于是 wiki中这个 get/set 接口函数出现在了每一个被绑定的函数里.一共4个button 出现4次
ps: 这个get/set接口本质上就是一个view刷新接口
事情仍在在酝酿:
产品大爷发话了,要改成下面这样:

多了一个求和.
于是伪代码变成了这样:
`购买苹果按钮`绑定事件如下:
1.int 苹果数变量 + 1;
2.int 总和变量 = 苹果数变量 + 梨数变量;
2.显示苹果数控件的值 = 苹果数变量;
3.显示总和控件的值 = 总和变量;
这次 程序员B为了人身安全,提前把 get/set 接口发布到了 wiki上..
于是 总和控件的值 = 总和变量 这行代码出现了 4次.
产品存在的意义,就是将程序狗虐到极致:
于是需求改成了这样:

只是删了一行.
于是 4个函数中 所有相关代码都被删除... 共影响 4行代码..
段子讲完了,其核心问题在于,按照事件进行的业务模块划分,有时候是不合理的,事件是用户行为的入口,但不是程序逻辑的入口. 一个button的click就可能横跨N个领域, 需要N个人来进行协作, 这部分逻辑到最后还是会耦合在一起,通过各种函数封装进行解耦,无疑是扬汤止沸,而我们需要的是釜底抽薪
三代目: M-V-C:(模型,视图,控制器)

现在网上有很多关于mvc的介绍,让人纠结的是他们各不相同,而且有的根本就说的不对, 对于框架模式这东西,没有一个严格的规定说这样搞是 mvc 那样就不是. 甚至连mvc本身也有很多变种,我们只要从根源上理解这个东西就行.
我就不扒祖坟了,咱们只需要知道它已经存在了 30多年就行了.
我们思考一下 UI(图形化用户界面) 的本质:
为什么要有UI, 在计算机眼中 一切即数据,其实要是深挖这个问题,数据与操作其实都是 0 1 组成的机器码,只不过 CPU运行的时候用指定寄存器的数据当做指令罢了,也就是说 决定一个数据到底是数据还是指令 只取决于他所在的寄存器位置.(好了好了 扯远了,往回跑..) 数据的操作是抽象的,是专业人士干的事情, 计算机为了走进千家万户, 必须提供一种傻瓜式的操作方式,于是UI诞生了... 用一句话解释UI就是:他是数据到图像的一种映射程序;
刚才说了它是一种映射程序,用户通过操作图像上的按钮,来达到操作数据的目的,数据被用户改变后,肯定需要从新生成映射.
请允许我向上一张老掉牙的图:
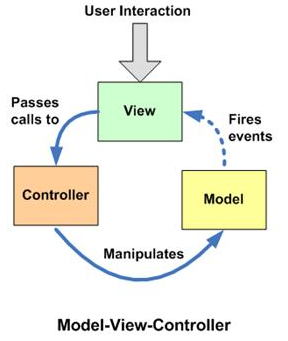
说说这里面 Modle View Controller 是干什么的:
1.View: 放置视图相关的代码,原则上里面不应该有任何业务逻辑.
2.Controller: 放置视图与模型之间的映射,原则上这里应该很薄,他只放一些事件绑定相关的代码(router),但并不实现真正的功能,他只是一个桥梁.
3.Modle: 这里的modle不是说 实体类, 他是主要实现逻辑的地方.
那还是上面 买水果的例子,那么在MVC下该如何设计呢:
| 概念 | 解释 |
|---|---|
| view层 | 放置界面代码,以及一些刷新逻辑 如数据中的 0 1 转成 男 女 |
| controller层 | 放置一些绑定逻辑.完成router,不实现函数体. |
| model层 | 接收view的注册,当自身数据变化时,执行view的刷新函数. 业务逻辑都在这里 |
他是这样一个流程:
1.创建显示苹果数量的控件.
2.将上面控件注册到model中.(设置关联的数据,--苹果数变量)
3.修改model中 苹果数变量 .
4.由于苹果数变量被修改,触发所有绑定在上面的控件(view)从新执行刷新函数.
5.显示苹果数量的控件被更新.
这样便解决了大部分界面与逻辑耦合的问题,但是它并不完美:
-
View 和 Model 并不是完全脱离的,还是有一些逻辑耦合,因为需要根据修改后的model从新刷新view. 难免view里面沾染一点model的结构.
-
代码量膨胀.
-
不方便进行更精细的颗粒化控制.(因为view只知道 model被改了,但不知道谁改的!)
- model在对应多个view的时候,很难都伺候到位.
于是...
四代目: M-V-P:(模型,视图,派发器)

请允许我再上一张老图:
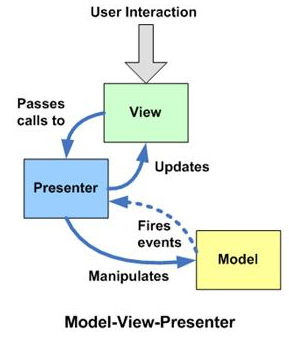
针对mvc的一些问题,在mvp模式下, 斩断了 view 与 model的关系, 当m 改变时,m 通知 p 去改变v, 所以v变得更纯洁(刷新逻辑被移动到了p层), 为了保证m可以最大程度的复用 一部分业务逻辑也从 m 转移到了p所以 mvp下 p 非常厚实.
mvp中最后改变v的是p那么在 v与p 之间会有一个接口,解决怎么转换以及传值的问题.
五代目: M-V-VM:(模型,视图,抽象视图)
MVVM,最早来自于微软社区,用于WPF

Model-View-ViewModel的关系图:

mvvm 与 mvp 的最大区别就是它使用 数据绑定(Data Binding)、依赖属性(Dependency Property)、命令(Command)、路由事件(Routed Event) 来搞定与view层的交互, 但是这种绑定是与某种具体技术栈相关的, ViewModel从Model中抽象而来,但更贴近于业务模型, 比如你Model中某字段是 true false, ViewModel中可能就是 "黑","白"等 这种更贴近业务场景的描述. ViewModel中的属性直接与某具体控件的属性相绑定. 也就是说当某具体控件发生变化,ViewModel中的 某个字段就会跟着变化,然后Model中的字段也会进一步变化.
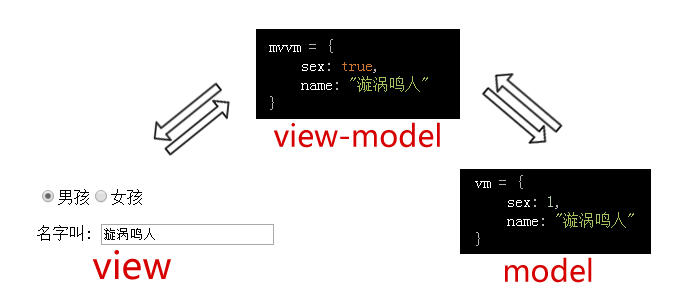
以上述为例:
用户使用UI修改了性别字段:
1.操作触发绑定在UI上的事件(Data Binding 自动完成)
2.事件进入vm层,根据绑定规则,找出对应的vm字段, (如表示性别的组件绑定的是vm中的sex字段)
3.vm上的sex被设置成true,(view层上值为"男" "女",但是在抽象的vm层中我们用 bool 来表示这个字段)
4.同理寻找m层上的对应字段,m上的sex被vm修改成1
5.m找到所有与sex字段有绑定关系的vm通知他们更新.
6.所有接到通知的vm更新sex字段.
7.vm寻找所有与sex字段有绑定关系的view层控件,通知他们更新(Data Binding 自动完成).
8.view被更新.所有涉及到sex字段的组件都被刷新.
有时候这个流程未必是从 1 步开始,如果直接对 m 进行修改,则就是从第 4 步开始的.
同理如果没有view层,则没有必要进行 7 , 8步骤.
这就是说 mvvm 下可以完全干掉 view 层, 方便的进行自动化测试.
小结 (推送/订阅 这个是数据驱动的核心)
不管是 mvc 还是 mvp 或 mvvm ,他们都是 数据驱动 的.核心上基于 m 推送消息,v或p来订阅 这个模型.使用者需要维护的不再是 UI 树,而是抽象的数据.(通过数据,可以随时构建出新的 UI 树), 当 UI 的状态一旦多起来,这种框架模式的优势便体现出来了. 因为维护数据可比维护 UI 状态爽多了.
前端中的mvc:
并不是说 m v c 三者一定要独立出现才行,比如 Backbone.js 它的 controller 层只是一个 router. 其实在传统 mvc 中 controller 里本来就没有太多的逻辑,他只是 一个事件的"传递者", 加之 javascript 中人们习惯使用匿名函数当事件回调,这样就等于直接在 view 层中把功能函数实现了. 所以 view 与 controller 合并 或者 controller 与model 合并都有可能.
$(xxx).click(function(e){
console.log(e);
})